Some netizens asked questions on Quora, "What is the most powerful program/script you have written in Python?". This article is an excerpt from several small projects of three foreign programmers, including code.
Manoj Memana Jayakumar, 3000+ top
Update: With these scripts, I found a job! See my reply in this post, "Has anyone got a job through Quora? Or somehow made lots of money through Quora?"
1. Movie/TV subtitles one-click downloader
We often encounter such a situation, which is to open the subtitle website subscene or opensubtitles, search for the name of the movie or TV series, then select the correct crawler, download the subtitle file, extract, cut and paste it into the folder where the movie is located, and The subtitle file needs to be renamed to match the name of the movie file. Is it too boring? By the way, I wrote a script to download the correct movie or TV subtitle file and store it in the same location as the movie file. All the steps can be completed with just one click. Is it forced?
Please watch this Youtube video: https://youtu.be/Q5YWEqgw9X8
The source code is stored in GitHub:subtitle-downloader
Update: Currently, the script supports simultaneous download of multiple subtitle files. Steps: Hold down Ctrl and select the multiple files for which you want to download subtitles. Finally, execute the script.
2. IMDb Query / Spreadsheet Generator
I am a movie fan and like to watch movies. I always get confused about which movie to watch because I have collected a lot of movies. So, what should I do to eliminate this confusion and choose a movie to watch tonight? That's right, it's IMDb. I open http://imdb.com, enter the name of the movie, watch the rankings, read and comment, and find a movie worth watching.
However, I have too many movies. Who would want to enter the names of all the movies in the search box? I certainly won't do this, especially if I believe "if something is repetitive, then it should be automated." So I wrote a python script to get the data using the unofficial IMDb API. I select a movie file (folder), right click, select 'Send to', then click IMDB.cmd (by the way, IMDB.cmd is the python script I wrote), and that's it.
My browser will open the exact page of this movie on the IMDb website.
The above operation can be done with just one click of a button. If you can't understand how cool this script is and how much time it can save you, check out this Youtube video: https://youtu.be/JANNcimQGyk
From now on, you no longer need to open your browser, wait for the IMDb page to load, and type the name of the movie. This script will do all the work for you. As usual, the source code is placed on GitHub:imdb with instructions. Of course, since this script must remove meaningless characters in files or folders, such as "DVDRip, YIFY, BRrip", etc., there will be a certain percentage of errors when running the script. But after testing, this script works fine on almost all my movie files.
2014-04-01 update:
Many people are asking if I can write a script that can find the details of all the movies in a folder, because it is very troublesome to find the details of one movie at a time. I have updated this script to support processing the entire folder. The script analyzes all the subfolders in this folder, grabs the details of all the movies from IMDb, and then opens a spreadsheet that sorts all the movies in descending order, according to the ranking on IMDb. This table contains (all movies) in IMDb URL, year, plot, category, award information, cast information, and other information you may find at IMBb. The following is an example of a table generated after the script is executed:
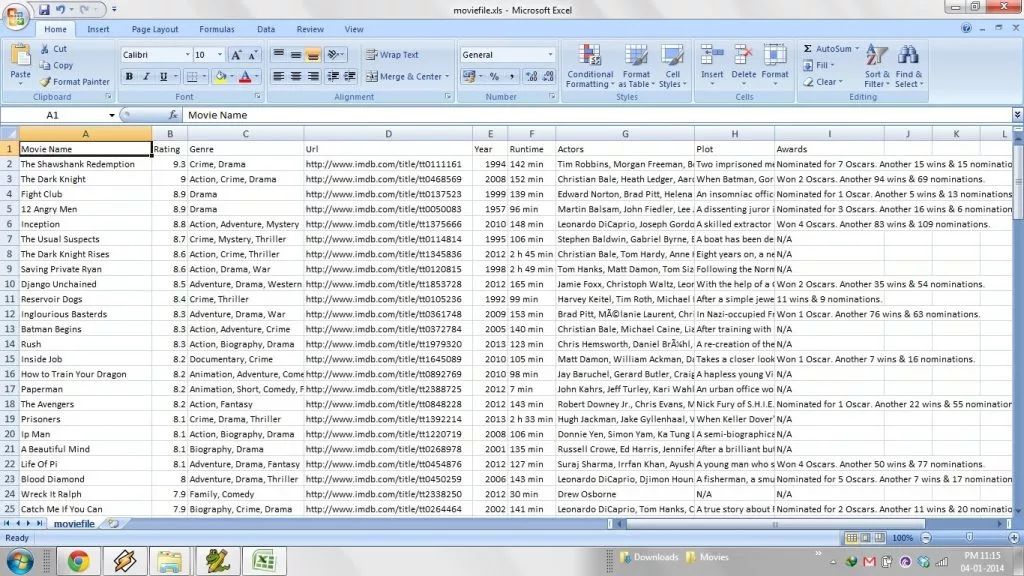
Your very own personal IMDb database! What more can a movie buff ask for? ;)Source on GitHub:imdb
You can also have a personal IMDb database! Can a movie fan still ask for more? :)
Source code in GitHub:imdb
3. theoatmeal.com serial comic downloader

I personally like Matthew Inman's comics. They are crazy and funny, but they are thought-provoking. However, I am tired of repeatedly clicking on the next one before I can read every comic. In addition, since each comic is composed of Dover images, it is very difficult to manually download these comics.
For the above reasons, I wrote a python script to download all the comics from this site. This script uses BeautifulSoup (http://B...) to parse HTML data, so you must install BeautifulSoup before running the script. The downloader for downloading oatmeal (a comic book by Matthew Ingman) has been uploaded to GitHub: theoatmeal.com-downloader. (Manga) After downloading the folder is like this: D
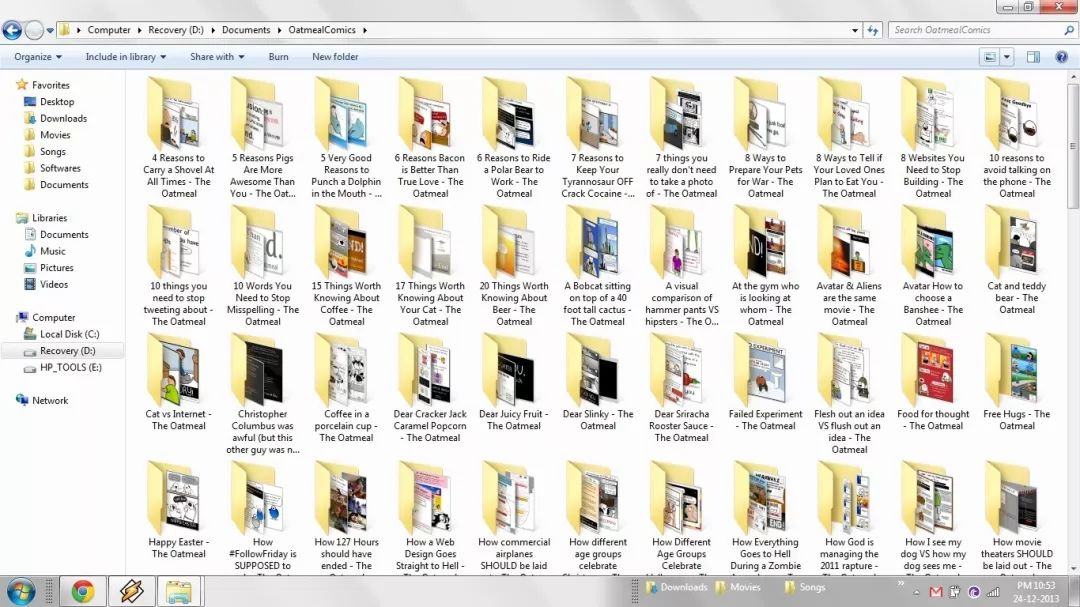
4. someecards.com Downloader
After successfully downloading the entire comic from http://, I was wondering if I could do the same thing, from another site I liked - funny, the only http:// download something?

The problem with somececards is that the image naming is completely random, all images are not in a specific order, and there are a total of 52 large categories, each with thousands of images.
I know that if my script is multi-threaded, it would be perfect because there is a lot of data to parse and download, so I assign a thread to each page in each category. This script will download funny e-cards from each individual category of the site and put each one in a separate folder. Now, I have the most private e-card collection on the planet. After the download is complete, my folder looks like this:
That's right, my private collection includes: 52 categories, 5036 e-cards. The source code is here: someecards.com-downloader
EDIT: A lot of people ask me if I can share all the files I downloaded (here, I want to say). Because my network is not stable, I can't upload my favorites to the network hard drive, but I have uploaded a seed file. , you can download it here: somecards.com Site Rip torrent
Plant seeds, spread love :)
Akshit Khurana, 4400+ top
Thanks to more than 500 friends for sending me birthday wishes on Facebook.
There are three stories that make my 21st birthday unforgettable. This is the last story. I tend to personally comment on each blessing, but using python to do better.
#谢谢ing everyone who wished me on my birthdayimport requestsimport json# Aman's post timeAFTER = 1353233754TOKEN = ' 'def get_posts(): """Returns dictionary of id, first names of people who posted on my wall between start and end time""" Query = ("SELECT post_id, actor_id, message FROM stream WHERE " "filter_key = 'others' AND source_id = me() AND " "created_time > 1353233754 LIMIT 200") payload = {'q': query, 'access_token': TOKEN } r = requests.get('https://graph.facebook.com/fql', params=payload) result = json.loads(r.text) return result['data']def commentall(wallposts): "" "Comments thank you on all posts""" #TODO convert to batch request later for wallpost in wallposts: r = requests.get('https://graph.facebook.com/%s' % wallpost['actor_id']) Url = 'https://graph.facebook.com/%s/comments' % wallpost['post_id'] user = json.loads(r.text) message = 'Thanks %s :)' % user['first_name' ] payload = {'access_token': TOKEN, 'messa Ge': message} s = requests.post(url, data=payload) print "Wall post %s done" % ​​wallpost['post_id']if __name__ == '__main__': commentall(get_posts())
In order to run the script smoothly, you need to get the token from the Graph API Explorer (with appropriate permissions). This script assumes that all posts after a specific timestamp are birthday wishes.
Despite a little change to the comment feature, I still like every post.
When my clicks, comments, and comment structures pop up in ticker (a feature of Facebook, friends can see what another friend is doing, such as likes, listen to songs, watch movies, etc.), one of my Friends soon discovered that this matter must be flawed.
Although this is not my most satisfying script, it is simple, fast and fun.
When I was discussing with Sandesh Agrawal in the web lab, I had the idea to write this script. To this end, Sandesh Agrawal expressed his deep gratitude for the delay in laboratory work.
Tanmay Kulshrestha, 3300+ top
Ok, before I lost this project (a pig-like friend formatted my hard drive, all my code was on that hard drive) or, before I forgot the code, I decided to answer the question.
Organize photos
After I was interested in image processing, I was always working on machine learning. I wrote this interesting script in order to categorize the images, much like what Facebook does (of course this is an algorithm that is not precise enough). I used OpenCV's face detection algorithm, "haarcascade_frontalface_default.xml", which detects faces from a single photo.

You may have noticed that some parts of this photo were mistakenly recognized as faces. I tried to fix some parameters (to fix this problem), but some places were mistakenly recognized as faces, which is caused by the relative distance of the camera. I will solve this problem in the next stage (training steps).
This training algorithm requires some training material, and each person needs at least 100-120 training materials (of course, more good). I was too lazy to pick photos for everyone and copy them to the training folder. So, as you may have guessed, this script will open a picture, recognize the face, and display each face (the script will predict each face based on the training material at the current node). With each photo you tag, Recognizer will be updated and will include the last training material. You can add new names during the training process. I made a GUI using the python library tkinter. Therefore, most of the time, you have to initialize a small part of the photo (name the face in the photo), and other work can be given to the training algorithm. So I trained Recognizer and then let it (Recognizer) handle all the images.
I use the name of the person contained in the image to name the image (for example: Tanmay&*****&*****). Therefore, I can traverse the entire folder and then search for the image by entering the name of the person.
In the initial state, when a face has no training material (the name of the face is not included in the material library), you need to ask his/her name.
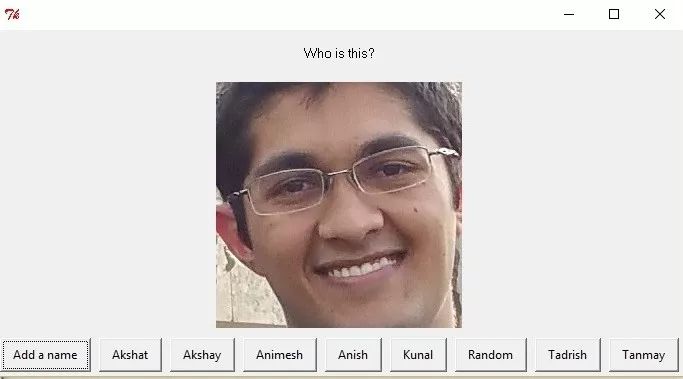
I can add a name like this:
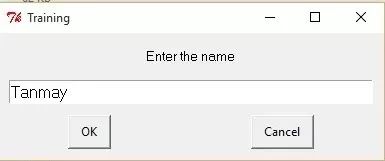
When you train a few pieces of material, it will look like this:

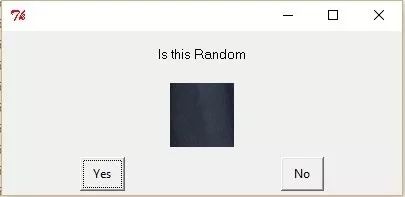
The last one is a workaround for dealing with spam random blocks.
The final folder with the name.

So now looking for pictures has become quite simple. By the way, I am sorry (I) to enlarge these photos.
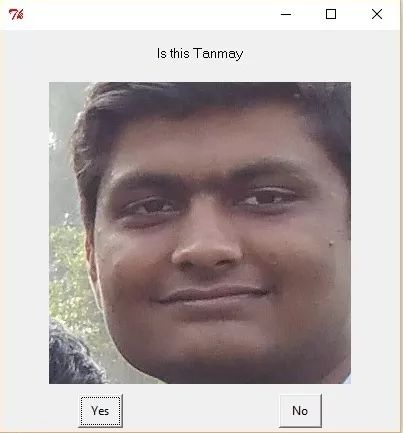
Import cv2import sysimport os,random,string#choices=['Add a name']import oscurrent_directory=os.path.dirname(os.path.abspath(__file__))from Tkinter import Tkfrom easygui import *import numpy as npx= os. Listdir(current_directory)new_x=[]testing=[]for i in x:if i.find('.')==-1:new_x+=[i]else:testing+=[i]x=new_xg=xchoices=[ 'Add a name']+xy= range(1,len(x)+1)def get_images_and_labels():global current_directory,x,y,gif x==[]:return (False,False)image_paths=[]for i in g:path=current_directory+''+ifor filename in os.listdir(path):final_path=path+''+filenameimage_paths+=[final_path]# images will contains face imagesimages = []# labels will contain the label that is assigned to The imagelabels = []for image_path in image_paths:# Read the image and convert to grayscaleimg = cv2.imread(image_path,0)# Convert the image format into numpy arrayimage = np.array(img, 'uint8')# Get the label Of the imagebackslash=image_path.rindex('')underscore=image_path.index('_',backslash)nbr = image_path[backslash +1:underscore]t=g.index(nbr)nbr=y[t]# If face is detected, append the face to images and the label to labelsimages.append(image)labels.append(nbr)#cv2.imshow ("Adding faces to traning set...", image)#cv2.waitKey(50)# return the images list and labels listreturn images, labels# Perform the traniningdef train_recognizer():recognizer = cv2.createLBPHFaceRecognizer()images, labels = get_images_and_labels()if images==False:return Falsecv2.destroyAllWindows()recognizer.train(images, np.array(labels))return recognizerdef get_name(image_path,recognizer):global x,choices#if recognizer=='': # recognizer=train_recognizer()cascadePath = "haarcascade_frontalface_default.xml"faceCascade = cv2.CascadeClassifier(cascadePath)#recognizer=train_recognizer()x1=testingglobal gprint image_pathimage = cv2.imread(image_path)img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY )predict_image = np.array(img, 'uint8')faces = faceCascade.detectMultiScale(img,scaleFactor=1.3,minNeighbors=5,minSize=(30, 30),flags = http://cv2 .cv.CV_HAAR_SCALE_IMAGE)for (x, y, w, h) in faces:f= image[y:y+w,x:x+h]cv2.imwrite('temp.jpg',f)im='temp .jpg'nbr_predicted, conf = recognizer.predict(predict_image[y: y + h, x: x + w])predicted_name=g[nbr_predicted-1]print "{} is Correctly Recognized with confidence {}".format(predicted_name , conf)if conf>=140:continuemsg='Is this '+predicted_namereply = buttonbox(msg, image=im, choices=['Yes','No'])if reply=='Yes':reply=predicted_namedirectory= Current_directory+''+replyif not os.path.exists(directory):os.makedirs(directory)random_name=''.join(random.choice(string.ascii_uppercase + string.digits) for _ in range(7))path= Directory+''+random_name+'.jpg'cv2.imwrite(path,f)else:msg = "Who is this?"reply = buttonbox(msg, image=im, choices=choices)if reply == 'Add a name' :name=enterbox(msg='Enter the name', title='Training', strip=True)print namechoices+=[name]reply=namedirectory=current_directory+''+replyif not os.path.exists(directory):os. Makedirs(directory)random_name=''.join(random.choice (string.ascii_uppercase + string.digits) for _ in range(7))path=directory+''+random_name+'.jpg'print pathcv2.imwrite(path,f)# calculate window positionroot = Tk()pos = int(root .winfo_screenwidth() * 0.5), int(root.winfo_screenheight() * 0.2)root.withdraw()WindowPosition = "+%d+%d" % pos# patch rootWindowPositionrootWindowPosition = WindowPositiondef detect_faces(img):global choices,current_directoryimagePath = imgfaceCascade = cv2.CascadeClassifier(cascPath)image = cv2.imread(imagePath)gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)faces = faceCascade.detectMultiScale(gray,scaleFactor=1.3,minNeighbors=5,minSize=(30, 30) ,flags = http://cv2.cv.CV_HAAR_SCALE_IMAGE)print "Found {0} faces!".format(len(faces))m=0for (x, y, w, h) in faces:m+=1padding=0f = image[y-padding:y+w+padding,x-padding:x+h+padding]cv2.imwrite('temp.jpg',f)im='temp.jpg'msg = "Who is this?" Reply = buttonbox(msg, image=im, choices=choices)if reply == 'Add a name':name=enterbox(msg='Enter the name', title='Training', strip=T Rue)print namechoices+=[name]reply=namedirectory=current_directory+''+replyif not os.path.exists(directory):os.makedirs(directory)random_name=''.join(random.choice(string.ascii_uppercase + string. Digits) for _ in range(7))path=directory+''+random_name+'.jpg'print pathcv2.imwrite(path,f)def new(img,recognizer):imagePath = current_directory+''+imgprint imagePathget_name(imagePath,recognizer )cacPath = 'haarcascade_frontalface_default.xml'b=0os.system("change_name.py")for filename in os.listdir("."):b+=1if b%10==0 or b==1:os.system ("change_name.py")recognizer=train_recognizer()if filename.endswith('.jpg') or filename.endswith('.png'):print filenameimagePath=filename#detect_faces(imagePath)new(imagePath,recognizer)os. Remove(filename)raw_input('Done with this photograph')
I want to further modify its search function, which will include more search types, such as based on location, smiling face, sad face and so on. (So ​​I can search for Happy Tanmay & Frustrated Akshay & Happy on Skylawns...)
I also wrote a lot of scripts, but that was a long time ago, and I am too lazy to check the code again. I will list some of the code.
GitHub link: tanmay2893/Image-Sorting
Gmail mail notification
During that time, I didn't have a smartphone. As a result, I often missed emails from my research institute (in my research email ID), I wrote a script that can be run on my laptop and can send messages to my mobile phone. I am using python's IMAP library to get mail. I can enter the names of some important people, so that when these people send me an email, I can receive a text message. For SMS, I used way2sms.com (written a python script, automatically logged into my account, and then sent a text message).
PNR (Passenger Name Record passenger reservation record, the same below) Status SMS
Railways do not frequently send PNR status messages. Therefore, I wrote a script to get the PNR status from the Indian Railways website. This is very easy, because that site does not have a verification code, even if it is, it is just a fake verification code (in the past, some letters will be written on things that look like pictures, because they use a "for these letters" Background image of check"). We can easily get these letters from the HTML page. I don't understand what they are doing, is it just to fool themselves? Anyway, I use a short message script to process it. After a period of time, it will run once on my laptop, like a timed task. As long as the PNR status is updated, it will send the update information to me. .
YouTube Video Downloader
This script will download all Youtube videos and all their subtitle files (downloaded from Download and save subtitles) from the Youtube page. In order to make the download faster, I used multithreading. Another feature is that you can pause and resume playback of the downloaded video even if your computer is rebooted. I originally wanted to be a UI, but I was too lazy... Once my download task is complete, I don't care about the UI.
Cricket score notifier
I guess this feature has already been mentioned elsewhere. A window notifier. (In the notification area in the lower right corner, it will tell you the live score and the comment information). If you are willing to do so, you can turn it off at certain times.
WhatsApp message
This is not very practical, I just wrote and played. Because Whatsapp has a web version, I use selenium and Python to download the display images of all my contacts, and I will know once someone has updated their display image. (How to do it? Very simple, after setting the time interval, I will download all the avatar information over and over again. Once the size of the photo changes, I will know that he/she has updated the display image) . Then I will send him/her a message, a good avatar. I only used it once to test its usability.
Nalanda Downloader
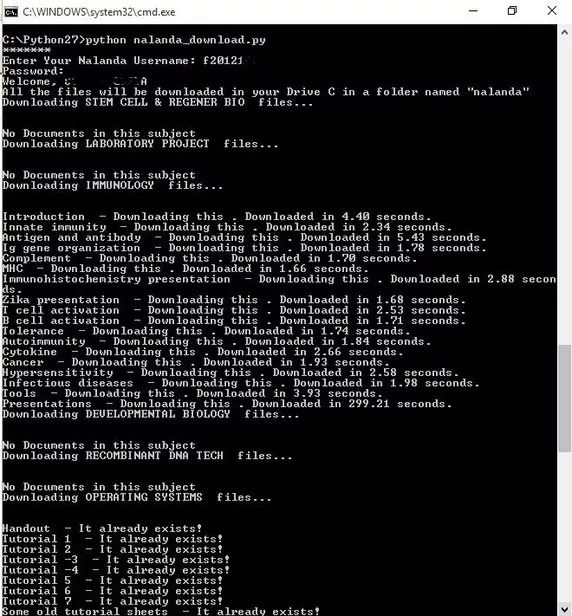
We usually download some teaching courseware and other course materials on this website called 'Nalanda', 'Nalanda' in BITS Pilani (Nalanda). I am too lazy to download all the courseware one day before the exam, so I wrote this one. Downloader, which can download the courseware of each subject to the corresponding folder.
Code:
Import mechanize, os, urllib2, urllib, requests, getpass, timestart_time = time.time() from bs4 import BeautifulSoupbr=mechanize.Browser()br.open('https://nalanda.bits-pilani.ac.in/login /index.php')br.select_form(nr=0) name=''while name=='': try: print '*******' username=raw_input('Enter Your Nalanda Username: ') password =getpass.getpass('Password: ') br.form['username']=username br.form['password']=password res=br.submit() response=res.read() soup=BeautifulSoup(response) Name=str(soup.find('div',attrs={'class':'logininfo'}).a.string)[:-2] except: print 'Wrong Password'f=open('details.txt' , 'w')f.write(username+'n'+password)f.close()print 'Welcome, '+nameprint 'All the files will be downloaded in your Drive C in a folder named "nalanda"'#print soup .prettify()div=soup.find_all('div',attrs={'class':'box coursebox'})l=len(div)a=[]for i in range(l): d=div[i ] s=str(d.div.h2.a.string) s=s[:s.find('(')] c=(s,str(d.div.h2.a['href'])) Path='c:nala Nda'+c[0] if not os.path.exists(path): os.makedirs(path) a+=[c]#print aoverall=[]for i in range(l): response=br.open(a [i][1]) page=response.read() soup=BeautifulSoup(page) li=soup.find_all('li',attrs={'class':'section main clearfix'}) x=len(li) t=[] folder=a[i][0] print 'Downloading '+folder+' files...' o=[] for j in range(x): g=li[j].ul #print g #raw_input ('') if g!=None: temp=http://g.li['class'].split(' ') #raw_input('') if temp[1]=='resource': #print ' Yes' #print '********************' o+=[j] h=li[j].find('div',attrs={'class' :'content'}) s=str(h.h3.string) path='c:nalanda'+folder if path[-1]==' ': path=path[:-1] path+=''+s If not os.path.exists(path): os.makedirs(path) f=g.find_all('li') r=len(f) z=[] for e in range(r): p=f[e ].div.div.aq=f[e].find('span',attrs={'class':'resource Linkdetails'}).contents link=str(p['href']) text=str(p.find('span').contents[0]) typ='' if str(q[0]).find( 'word')!=-1: typ='.docx' elif str(q[0]).find('JPEG')!=-1: typ='.jpg' else: typ='.pdf' if Typ!='.docx': res=br.open(link) soup=BeautifulSoup(res.read()) if typ=='.jpg': di=soup.find('div',attrs={'class ':'resourcecontent resourceimg'}) link=di.img['src'] else: di=soup.find('div',attrs={'class':'resourcecontent resourcepdf'}) link=di.object[' Data'] try: if not os.path.exists(path+''+text+typ): br.retrieve(link,path+''+text+typ)[0] except: print 'Connectivity Issues' z+=[( Link,text,typ)] t+=[(s,z)] if t==[]: print 'No Documents in this subject' overall+=[o] #raw_input('Press any button to resume ')#print overallprint 'Time Taken to Download: '+str(time.time()-start_time)+ ' seconds'print 'Do you think you can download all files faster than this :P'print 'Closing in 10 seconds' Time.sleep(10)
My own DC++
This script is not very useful. Currently, only some students are using it. Moreover, DC++ has provided some cool features. I could have optimized my own version, but since we already have DC++, I didn't do that, even though I have written a base version using nodeJS and python.
working principle:
Open DC++, go to a central site, and connect, I wrote a python script to do this. The script creates a server on the PC (which can be done by modifying the SimpleHTTPRequestHandler).
On the server side (using NodeJS), it gets the connection to the PC and shares it with other users.
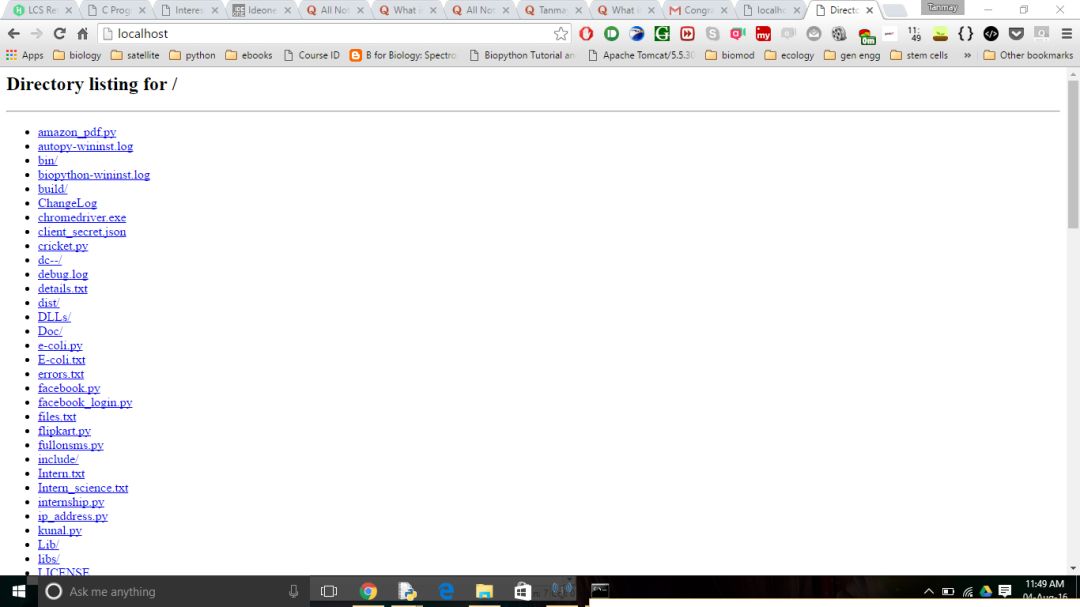
This is the main page:
This page shows all users and their links. Because I added a hyperlink to Nick, the link in the link is empty.
So, when the number of users increases, this page lists all the user lists. Basically, this page acts as a middleman role that you connect with another person. I also did a feature to search for specific files among all users.
Here is the client python file (this is a very long code, I uploaded it to Ideone)
All of this code is for educational purposes only.
English: Quora
Http://python.jobbole.com/85986/
The Puff Plus Disposable Pod Device that will fix any of your fruity cravings. It's from the same puff brand as Puff Bar. These puff plus have 800+ puffs each.Hot sale in many market, like USA, Australia,Russia,Vietnam,Mexico,Latvia,Dubai and so on.The puff bar plus Wholesale Vape Pen AIO system features a draw-activated firing mechanism. With a 550mAh internal battery & 3.2mL high potency nic salts and over 30+ flavors including menthol flavoring, these pods will deliver a soothing head change and a perfect fit for everyone. We have all puff bar plus flavors. Puff plus has the Most flavors of Any Disposable Vape Device on the Market more than 30+ types, such as apple ice, mixed berries, aloe grape, cool mins etc. As a professional disposable vape puff plus factory and supplier, we accept OEM Vape for puff bar plus etc.
Puff Bar Plus Vape,Puff Bar Plus Disposable,Puff Bar Plus Box,Puff Bar Plus Flavors
Shenzhen Kate Technology Co., Ltd. , https://www.katevape.com