Being a qualified development engineer is not a simple matter. It requires a range of capabilities, from development to commissioning to optimization. Each of these capabilities requires sufficient effort and experience.
To become a qualified machine learning algorithm engineer (hereinafter referred to as algorithm engineer) is even more difficult, because in addition to mastering the general skills of engineers, you also need to master a network of machine learning algorithms that is not too small.
Below we will split the skills required to be a qualified algorithmic engineer and see what skills are required to be considered a qualified algorithmic engineer.
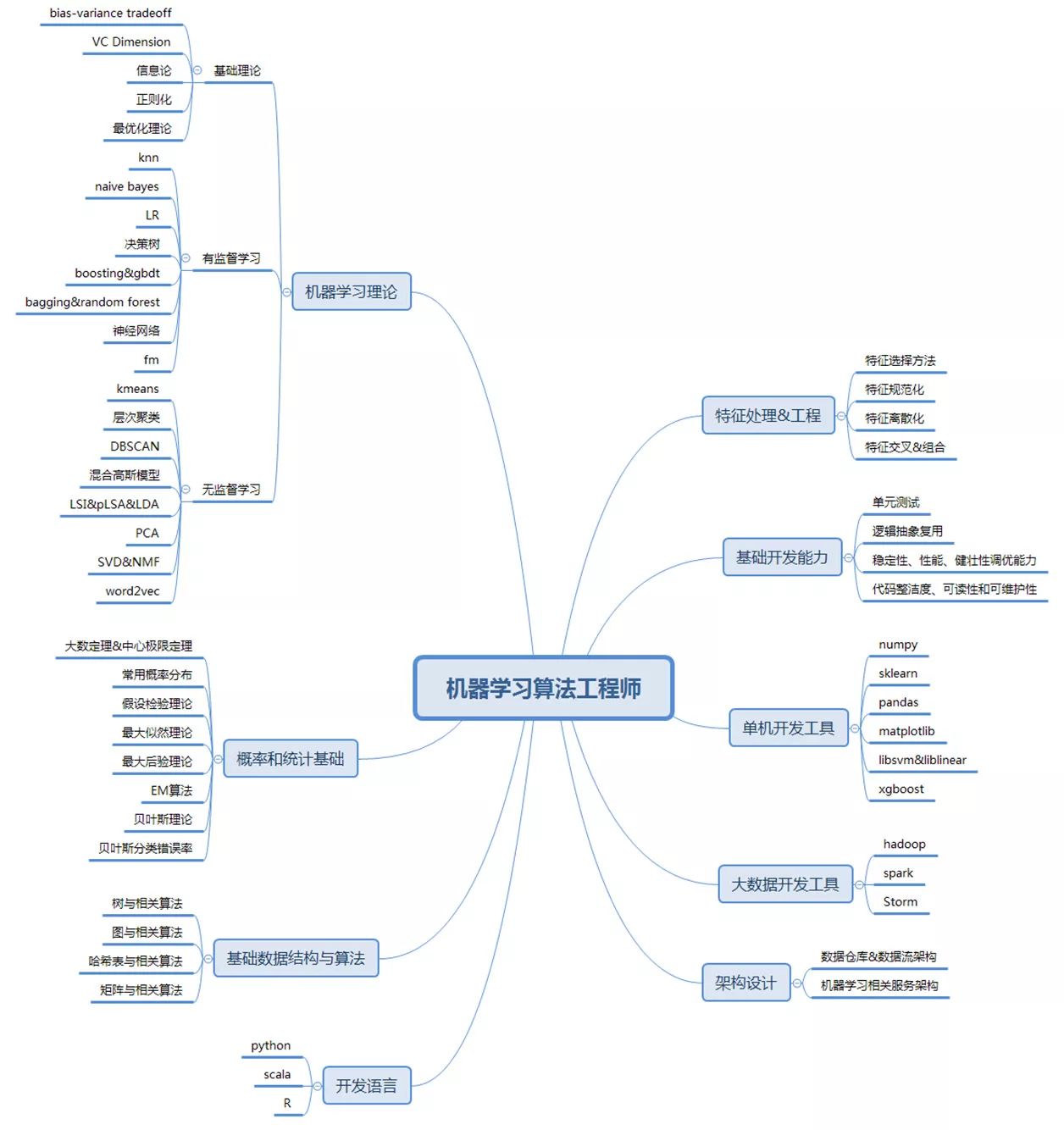
Figure 1 Machine Learning Algorithm Engineer Skill Tree
The so-called algorithm engineer needs to be an engineer first, so it is necessary to master some of the capabilities that all development engineers need to master. Some students have some misunderstandings about this point. They think that the so-called algorithm engineers only need to think and design the algorithm, don't care how these algorithms are implemented, and some people will help you to implement the algorithm solution you want. This kind of thinking is wrong. In most positions in most enterprises, the algorithm engineer needs to be responsible for the whole process from algorithm design to algorithm implementation to algorithm online.
I have seen some organizations have implemented an organizational structure that separates algorithm design from algorithm implementation. However, under this architecture, it is unclear who is responsible for the algorithm effect. Algorithm designers and algorithm developers have a bitter stomach. The reason is not in the scope of this article, but I hope that everyone remembers that the basic development skills are all that all algorithm engineers need to master.
There are so many skills involved in basic development, and only two important points are selected here for explanation.
unit testIn enterprise applications, a complete solution to a problem usually involves a lot of processes, each of which requires repeated iterations to optimize debugging, how to partition the complex tasks, and ensure the correctness of the overall process? The most practical method is unit testing. Unit testing is not just a simple test skill, it is first and foremost a design capability. Not every code can be unit tested. The premise of unit testing is that the code can be divided into multiple units—that is, modules. After disassembling the project into modules that can be independently developed and tested, plus independent, repeatable unit tests for each module, the correctness of each module can be guaranteed, if the correctness of each module is correct It can be guaranteed that the correctness of the overall process can be guaranteed.
For the development of such a process with frequent changes in algorithm development, module design and unit testing are important guarantees for not digging holes for themselves and others. It is also an important premise that allows you to confidently make various changes to your code.
Logical abstract reuseLogical abstract reuse can be said to be one of the most important principles of all software development activities. One of the important principles for measuring a programmer's code level is to look at the proportion of repeated code and similar code in his code. Behind a lot of repetitive code or similar code is the laziness of the engineer's thinking, because he feels that copying and pasting or directly copying is the most convenient way. Not only does this look very ugly, but it is also very error-prone, not to mention the difficulty of maintaining it.
There are often many similar logics in algorithm development projects, such as using similar processing methods for multiple features, and many similar processing methods in raw data ETL. If you don't abstract the repetitive logic, the code looks like a line-by-line repeating code, which can be cumbersome to read or maintain.
Probability and statistical basisProbability and statistics can be said to be one of the cornerstones of the field of machine learning. From a certain perspective, machine learning can be regarded as a systematic way of thinking and cognition of uncertain world based on probabilistic thinking. Learning to look at problems from a probabilistic perspective and describing problems in probabilistic language is one of the most important foundations for deep understanding and proficiency in machine learning techniques.
There are many contentes of probability theory, but they are all embodied by specific distributions. Therefore, the commonly used probability distribution and its various properties are very important for learning probability. For discrete data, Bernoulli distribution, binomial distribution, multinomial distribution, Beta distribution, Dirichlet distribution and Poisson distribution are all things that need to be understood; for offline data, Gaussian distribution and exponential distribution are important. Distribution. These distributions run through various models of machine learning, as well as in the various data of the Internet and the real world. Understand the distribution of data and know what to do with them.
In addition, the theory of hypothesis testing needs to be mastered. In this so-called big data era, the most deceptive is probably the data. Mastering the relevant theories such as hypothesis testing and confidence intervals, can we have the ability to distinguish the authenticity of data conclusions. For example, is there really a difference between the two sets of data, whether the indicator is really improved after a strategy is put on the line, and so on. This kind of problem is very common in practical work. If you don't have the relevant ability, it is equivalent to the big eyes of the big data era.
In terms of statistics, some commonly used parameter estimation methods also need to be mastered, such as maximum likelihood estimation, maximum a posteriori estimation, and EM algorithm. These theories, like the optimization theory, are theories that can be applied to all models and are the basis of the foundation.
Machine learning theoryAlthough more and more open source toolkits are out of the box, it does not mean that algorithm engineers can ignore the learning and mastery of the basic theory of machine learning. There are two main reasons for this:
Mastering the theory can be applied flexibly to various tools and techniques, rather than just applying them. Only on this basis can we truly have the ability to build a machine learning system and continuously optimize it. Otherwise, it can only be regarded as a machine learning brick worker, and an unqualified engineer. If there is a problem, it will not be solved, let alone optimize the system.
The purpose of learning the basic theory of machine learning is not only to learn how to build a machine learning system, but more importantly, these basic theories reflect a set of ideas and modes of thinking, including probabilistic thinking, matrix thinking, and optimization. Thinking and other sub-areas, this set of thinking modes is very helpful for the processing, analysis and modeling of data in today's big data era. If you don't have this kind of thinking in your mind, in the face of big data environment, you still use old non-probability, scalar thinking to think about the problem, then the efficiency and depth of thinking will be very limited.
The theoretical connotation and extension of machine learning is very wide. It is not an article that can be exhausted. So here I have listed some of the cores of comparison, and at the same time introduce the contents that are more helpful in practical work. After mastering these basic contents, everyone can master these basic contents. And continue to explore and learn.
Basic theoryThe so-called basic theory refers to some theories that do not involve any specific model, but only the "learning" itself. Here are some basic concepts that are useful:
VC dimension. The VC dimension is an interesting concept. Its main body is a class of functions that describe how many combinations of samples can be divided by such a function. What is the significance of VC dimension? It is that after you have selected a model and its corresponding features, you can probably know how large the data set can be classified by the choice of models and features. In addition, the size of the VC dimension of a class of functions can also reflect the possibility of over-fitting such functions.
Information theory. From a certain perspective, machine learning and information theory are two sides of the same problem. The optimization process of machine learning model can also be regarded as the process of minimizing the amount of information in the data set. The understanding of the basic concepts in information theory is of great benefit to the study of machine learning theory. For example, the information gain used in the decision tree to make the decision of the split decision, the information entropy to measure the amount of data information, etc., the understanding of these concepts is very helpful for the understanding of the machine learning problem. This section can be found in the book "Elements of Information Theory."
Regularization and bias-variance tradeoff. If the main contradiction in China at this stage is "the contradiction between the people's growing need for a better life and the development of unbalanced development," the main contradiction in machine learning is that the model should fit the data as much as possible and the model cannot be over-fitting. The contradiction between the data. One of the core techniques for resolving this contradiction is regularization. The specific method of regularization is not discussed here, but what needs to be understood is the idea behind various regularization methods: bias-variance tradoff. The balance and trade-off between different interest points is an important difference between various algorithms. Understanding this point is very important for understanding the core differences between different algorithms.
Optimization theory. The solution to most machine learning problems can be divided into two phases: modeling and optimization. The so-called modeling is the various methods that we will use to describe the problem later, and the optimization is the process of obtaining the optimal parameters of the model after the modeling is completed. There are many models commonly used in machine learning, but there are not so many optimization methods used behind them. In other words, many models use the same set of optimization methods, and the same optimization method can be used to optimize many different models. It is necessary to have a good understanding of the various common optimization methods and ideas, and it is helpful to understand the process of model training and to explain the effects of model training in various situations. This includes maximum likelihood, maximum a posteriori, gradient descent, quasi-Newton method, L-BFGS, etc.
There are still many basic theories of machine learning. You can start from the above concepts and use them as the starting point for learning. In the process of learning, you will encounter other content that needs to be learned, just like a network is slowly spread out. Constantly accumulate your knowledge. In addition to the famous courses of Andrew Ng, the open course of "Learning from Data" is also worth learning. This course has no background requirements. The content of the lecture is based on all the models. The foundation is very close to the kernel essence of machine learning. The Chinese version of this course is called "The Cornerstone of Machine Learning" and can also be found online. The lecturer is the student of the above English version of the lecturer.
Supervised learningAfter understanding the basic concepts of machine learning, you can enter the study of some specific models. In the current industrial practice, the application of supervised learning is still the most extensive, because many of the problems we encounter in reality are to make predictions about a certain property of a certain thing, and these problems are reasonable. Both abstraction and transformation can be translated into supervised learning problems.
Before learning a complex model, I suggest that you first learn a few of the simplest models, typically Naïve Bayes. Naïve Bayes has a strong assumption. This assumption is not satisfied with many problems, and the model structure is very simple, so the optimization effect is not the best. But because of its simple form, it is very helpful for learners to deeply understand every step of the modeling and optimization process of the entire model, which is very useful for figuring out how machine learning is going back. At the same time, the model form of Naive Bayes can obtain a very uniform result in the form of logistic regression through a subtle transformation, which undoubtedly provides an explanation for another angle of logistic regression, for a deeper understanding of logistic regression. The most commonly used models have a very important role to play.
After mastering the basic process of the machine learning model, you need to learn the two most basic model forms: linear model and tree model, which correspond to linear regression/logical regression and decision regression/classification tree. The commonly used models, whether shallow models or deep learning deep learning models, are based on the changes of these two basic model forms. The question that needs to be carefully considered when learning these two models is: What are the essential differences between the two models? Why do you need these two models? What are the differences in the accuracy, efficiency, and complexity of training and prediction? Once you understand these essential differences, you can use the model freely based on the problem and the specifics of the data.
After mastering the two basic forms of linear model and tree model, the next step is to master the complex forms of the two basic models. The complex form of the linear model is the multi-layer linear model, which is the neural network. The complex forms of the tree model include a boosting combination represented by GDBT and a bagging combination represented by a random forest. The significance of these two combined models is not only the model itself, but also the combination of boosting and bagging. It is also worth learning and understanding. This represents two general methods of reinforcement: the idea of ​​boosting is excellence, and the foundation is constantly Continue to optimize; and the idea of ​​bagging is "three skunks will be the top one," is a combination of multiple weak classifiers to get a strong classifier. These two combination methods have their own advantages and disadvantages, but they are all ideas that can be used in daily work. For example, in the recommendation system, we often use multiple dimensions of data as the recall source. From a certain point of view, it is a bagging idea: each individual recall source does not give the best performance, but multiple recall sources. Once combined, you get better results than each individual recall source. So thinking is more important than the model itself.
Unsupervised learningSupervised learning currently accounts for most of the scenarios of machine learning applications, but unsupervised learning is also very important both in terms of data size and role. A large class of unsupervised learning is doing clustering. The meaning of clustering can usually be divided into two categories: one is to use the clustering result itself as the final goal, and the other is to use the clustering result as a result. Features are used in supervised learning. But these two meanings are not specifically bound to a certain clustering method, but only the different ways of using the results after clustering, which requires continuous learning, accumulation and thinking in the work. What needs to be mastered in the introductory learning phase is where the core differences between different clustering algorithms are. For example, in the most commonly used clustering methods, what kind of problems are keanans and DBSCAN suitable for? What assumptions are there in the Gaussian mixture model? What is the relationship between documents, topics and words in LDA? It's best to put these models together to learn to understand the connections and differences between them, rather than treating them as isolated ones.
In addition to clustering, the emerging embedding representation in recent years is also an important method of unsupervised learning. The difference between this method and clustering is that the clustering method uses existing features to divide the data, while the embedded representation creates new features. This new feature is a new representation of the sample. This new representation provides a new perspective on data that provides new possibilities for data processing. In addition, although this practice is emerging from the NLP field, it has a strong universality and can be used to process a variety of data, and can get good results, so it has become a necessary skill.
The study of machine learning theory can begin with "An Introduction to Statistical Learning with Application in R." This book provides a good explanation of some common models and theoretical foundations, as well as a moderate amount of exercises to consolidate what you have learned. Advanced learning can use the upgraded version of Elements of Statistical Learning and the famous Pattern Recognition and Machine Learning.
Development language and development toolsMastering enough theoretical knowledge and enough tools to bring these theories to the fore, this section introduces some common languages ​​and tools.
Development language
In recent years, Python can be said to be the hottest language in the field of data science and algorithm. The main reason is that it has a low threshold and is easy to use. At the same time, it has a complete tool ecosystem, and various platforms support it better. So I won't go into details about Python. But outside of learning Python, I suggest that you can learn about the R language again. The main reasons are as follows:
The R language has the most complete statistical tool chain. We introduced the importance of probability and statistics in the above. The R language provides the most comprehensive support in this respect. For some statistical needs, it may be faster to do it with R than with Python. Although Python's statistical science tools are constantly improving, R is still the largest and most active community in statistical science.
The cultivation of vectorization, matrixing and tabular thinking. All data types in R are vectorized, and an integer variable is essentially a one-dimensional vector of length one. On this basis, the R language builds efficient matrix and (DataFrame) data types, and supports very complex and intuitive methods of operation. This set of data types and ways of thinking are also adopted by many more modern languages ​​and tools, such as ndarray in Numpy and the DataFrame introduced in the latest version of Spark. It can be said that all are inspired directly or indirectly from R language. The data manipulation above is also the same as the operation of DataFrame and Vector in R. Just like learning to learn from C language, I want to learn about data science and algorithm development. I suggest that everyone learn about R. It is both its own language and its connotation. It is a mastery and understanding of modern tools. Great benefit.
In addition to R, Scala is also a language worth learning. The reason is that it is currently a language that combines object-oriented and functional programming paradigms better, because it does not force you to use functional formulas to write code, but also can be given where you can use functional formulas. Enough support. This makes its usage threshold not high, but with the accumulation of experience and knowledge, you can use it to write more and more advanced and elegant code.
development tools
In terms of development tools, Python-based tools are undoubtedly the most practical. Specifically, Numpy, Scipy, sklearn, pandas, and Matplotlib packages can satisfy most of the analysis and training work on a single machine. But in terms of model training, there are some more focused tools that give better training accuracy and performance, such as LibSVM, Liblinear, XGBoost, and so on.
In terms of big data tools, the mainstream tools for offline computing are still Hadoop and Spark. Spark Streaming and Storm are also the mainstream choices for real-time computing. There are also many new platforms that have emerged in recent years, such as Flink and Tensorflow are worthy of attention. It is worth mentioning that, for the mastery of Hadoop and Spark, not only must master the coding technology, but also have a certain understanding of its operating principle, for example, how the Map-Reduce process is implemented on Hadoop, what operation on Spark More time consuming, what is the difference between aggregateByKey and groupByKey in terms of running principle, and so on. Only by mastering these can you use these big data platforms freely, otherwise it is easy to have problems such as too long a program, no running, and a burst of memory.
Architecture designFinally, we spend some space to talk about the architectural design of the machine learning system. The so-called machine learning system architecture refers to a set of systems that support machine learning training, forecasting, and stable and efficient operation of services, and the relationship between them.
When the scale and complexity of the business develop to a certain extent, machine learning will definitely move toward the direction of systemization and platformization. At this time, it is necessary to design an overall architecture based on the characteristics of the business and the characteristics of the machine learning itself, including the architecture design of the upstream data warehouse and data flow, the architecture of the model training, and the architecture of the online service. The learning of this set of architecture is not as simple as the previous content. There are not many ready-made textbooks to learn, more abstract summarization based on a large number of practices, and continuous evolution and improvement of the current system. But this is undoubtedly the most worthwhile work for the algorithm engineer on the career path. The advice that can be given here is more practice, more summarization, more abstraction, and more iterations.
Current status of machine learning algorithm engineers
Now it can be said that it is the best era for machine learning algorithm engineers, and the demand for such talents in all walks of life is very strong. Typical include the following sub-sectors:
Recommended system. The recommendation system solves the problem of efficient matching and distribution of information in massive data scenarios. In this process, machine learning plays an important role in both the candidate set recall, the result sorting, and the user portrait.
Advertising system. There are many similarities between the advertising system and the recommendation system, but there are also significant differences. It is necessary to consider the interests of advertisers in consideration of both the platform and the users. The two parties become three parties, which makes some problems more complicated. It is similar to the recommendation in the use of machine learning.
Search system. Many of the infrastructure and upper-level sorting systems of the search system use machine learning technology extensively, and in many websites and apps, search is a very important traffic portal. The optimization of the search system by machine learning will directly affect the efficiency of the entire website. .
Wind control system. Wind control, especially Internet financial risk control, is another important battlefield for machine learning that has emerged in recent years. It is no exaggeration to say that the ability to use machine learning can largely determine the risk control ability of an Internet financial enterprise, and the risk control capability itself is the core competitiveness of these enterprises' business guarantees.
But the so-called "higher wages, greater responsibility", the company's requirements for algorithm engineers are gradually increasing. Overall, a high-level algorithmic engineer should be able to handle the complete process of “data acquisition → data analysis → model training tuning → model online†and continuously optimize various aspects of the process. When an engineer starts, he may start from one of the above processes and expand his ability.
In addition to the areas listed above, there are many traditional industries that are constantly learning the ability to solve traditional problems in excavators. The future of the industry has great potential.
We provide quick-turn injection molding by many types of materials, like ABS, PA66, PBT, TPU, TPE, PVC, PE, NYLON 6, PC, silicone, TPE, EPDM, PUR, etc. Special for some plastic parts. Our advantages in internal prototyping, bridge tooling and short-run manufacturing, which can eliminate the costly and time-consuming for customers a lot.
ETOP experienced to support one-stop cable assembly solution service, including wire harness, palstic enclosure, silicone, metal, PCBA, etc.
Injection Molding Parts,Plastic Injection Molding,Low Cost Plastic Injection Molding,Plastic Mold Injection Molding
ETOP WIREHARNESS LIMITED , https://www.wireharness-assembling.com