With the rapid development of network and multimedia technologies, people have put forward new requirements for video applications. Content-based interactive coding standard MPEG-4 is proposed to meet this requirement. The MPEG-4 video coding standard is oriented towards content coding. Video data is compressed, transmitted, edited, and retrieved in a content-based manner. The main difference from the previous video coding standards is the concept of objects. The input video is no longer full pixels Video objects, using video objects as the unit of operation to achieve all the functions of traditional encoding. Video objects are composed of scenes in a space-time relationship, but the foreground and background objects of the scene are encoded independently. As shown in Figure 1, there are two basic methods for composing video scenes based on video objects. Composed of video objects ((a) separate scenes), or existing video objects can be combined ((b) composed scenes). It is also possible that the scene is composed of the above two methods.
MPEG-4 video sequences are interpreted and processed according to video objects, which are defined by motion information, texture information, and shape information. MPEG-4 video packets are usually encoded based on the data separation mode, and shape information and motion information are independent of texture information and are transmitted separately. If the texture information is lost, texture error concealment can be performed using the correctly decoded shape information and motion information. If the shape and motion information are lost, the entire video packet is discarded.

Figure 1 The composition of the separated and composed scenes
The shape information is expressed by the Alpha mask plane, defined by two values ​​(1 for opaque, 0 for transparent), or gray level (the transparency of the pixel is between 0 and 255, 1 for opaque, 0 for Transparent). Generally, a binary mask plane is used, and each pixel position of the video object is defined as completely transparent or completely opaque. Binary shape information is sensitive to errors that occur on the network, and error diffusion can easily occur, which will affect the decoding of video objects in consecutive frames. Existing texture and motion information error hiding techniques are all correct to obtain shape information Obtained based on this, it shows that the shape error concealment is very necessary.
2 Review of shape error hiding technology
The MPEG-4 coding standard proposes error concealment techniques such as inserting synchronization codes, data segmentation, and reversible long coding. However, these technologies cannot meet the requirements for current communications. With the development of error concealment technology, and shape error concealment has gradually attracted the attention of many experts, some error concealment techniques about shape have also been proposed one after another. In this paper, some shape error concealment techniques in recent years are proposed.
The proposed techniques are nothing more than error concealment based on the natural properties of the image, which are divided into spatial domain error concealment and temporal domain error concealment. Spatial domain mainly focuses on the shape information of I-frame video objects, while temporal domain It is the shape information of the video object for P frame and B frame. The error concealment technology in the time domain is also based on the correct decoding of the shape information of the I frame, so the spatial error concealment is more meaningful. The method proposed in the literature is to use the maximum posterior estimation (MAP) model of the adaptive Markov domain to estimate the image in advance. Markov is designed for binary shape information, and the parameters are based on the information of adjacent blocks. Adaptation is determined. According to experiments, this method can accurately recover the shape information of the lost shape. Compared with the median filtering method, the method proposed in this paper can recover 20% of the lost information and obtain better objective quality. Curve interpolation method, which is simpler than adaptive Markov method, utilizes the characteristics of Hermite curve and Bayesian curve to hide the boundary error block according to the spatial continuity of the image. It uses time and motion information for error concealment.
These methods are to fix the error block on the decoding side, and also achieved good results, but the error rate targeted by these methods is limited, and once a serious error occurs, a large packet loss rate It is difficult to accurately recover the correct information. Not only that, if the characteristics of the details part of the curve are lost and the information cannot be recovered very accurately, these are very detrimental to the decoding of the video object, and if the shape information of the I frame is not recovered, then the time domain error concealment technology is used later The desired effect cannot be obtained.
3 The algorithm of this paper
Aiming at this problem, this paper proposes a novel method based on data hiding. This method is inspired by digital watermarking technology. Digital watermarking is a kind of information hiding technology. It is widely used in copyright issues such as images, videos, and audios. It has transparency, robustness, and provability. Therefore, digital watermarking technology is increasingly used in content authentication, etc. Other areas. This article is to use the characteristics of digital watermarking and shape error concealment technology, which is also the main innovation of this article. This article is mainly aimed at the error concealment of the shape of the I frame separating the video of the scene. The main idea proposed is to generate the watermark information to be embedded based on the shape information, and people pay less attention to the background objects as the embedding host.
Digital watermarking is divided into time domain / space domain watermark and frequency domain / transform domain watermark according to the embedding process. In general, frequency domain watermark is more robust and transparent than time domain watermark. This article uses these two different implementation methods respectively. The two methods are described below.
3.1 Using frequency domain watermark embedding method
The frequency domain method proposed in this paper is in the DCT transform domain. The specific implementation methods are as follows:
(1) First, the binary mask image is sampled and reduced to 1/4 of the original image. According to the principle of digital watermarking technology, the greater the amount of embedded information, the worse the transparency. The purpose of this is not to greatly affect the objective quality of the host image.
(2) The second is the selection of the host image. In this paper, the background object is selected as the host. The background object of the general video can be converted into three components of RGB. According to research, the green component has strong resistance to lossy compression. In order to completely embed the binary mask, the background objects that separate the scene are also interpolated, that is, the simplest horizontal interpolation method is used, and the average of the two non-zero values ​​adjacent to the zero pixel of each row is used to zero Value pixel bits are filled. The filled background image is used as the final host image.
(3) On the basis of the previous two steps, this paper chooses to embed the watermark information into the frequency domain information of the host image, divide the background image into 2 × 2 image blocks, perform DCT transformation on each block, and embed the watermark into the DCT In the IF coefficient of the coefficient, the selected IF coefficient is directly replaced with the value of the watermark.
(4) Finally, the watermark is extracted, and the binary mask image is restored. Extraction is the inverse process of embedding, directly dividing the received background image into 2 × 2 image blocks, performing DCT transformation on each block, directly extracting the selected intermediate frequency coefficients, and enlarging the extracted binary image Up to 4 times the original, so that the recovered binary mask image is obtained.
3.2 Embedding method using airspace watermark
The watermarking algorithm used in this paper is in X. Based on the algorithm proposed by Kang et al., The shape information used as the watermark is the original mask binary image without any change. Methods as below:
(1) The obtained watermark image to be embedded is embedded using the formula (1).

In the formula, rood is a modular operation, [α / 4, 3α / 4] is a pair of best parameter choices, he guarantees that both 0 and 1 have the same maximum decision range, so that f ’and The difference is between [-0.5α, 0.5α]. When w (m, n) = 1, f (m, n) mod α = 3α / 4; when ω (m, n) = 0, f (m / n) modα = α / 4. Therefore, when extracting the watermark, f * satisfies f * (m, n) mod α> α / 2, then the extracted watermark value is ω * (m, n) = 1, otherwise it is 0.
(2) The watermark embedding algorithm used in this paper belongs to blind watermark detection, and the extraction process does not require the participation of the original carrier image. The embedded watermark data ω * (m, n) is extracted according to formula (2).
The extracted watermark data ω * (m, n) is the recovered mask binary image. This watermark embedding method will have a certain degree of loss on the background image quality, and the degree of loss is related to the parameter α selected when embedding the watermark. But the extraction of watermark is also related to this parameter. In order for r to correctly recover the watermark value, the absolute error between f * and / (caused by image distortion) must be less than α / 4. The proper choice of the parameter α here can well compromise the transparency of the watermark and The contradiction between robustness. Larger α has a greater loss of image, while smaller is not conducive to the robustness of watermarking. According to the simulation experiment test, the value of a here is 20. According to experimental comparison, the loss of image quality is still tolerable when the alpha parameter is 20.
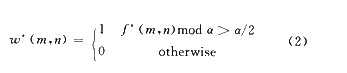
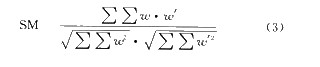
4 Simulation results
The Matlab simulation tool is used for the algorithm proposed in this paper, and the 50th frame image in the classic video sequence "Foreman" is tested according to the above method. The original video frame is shown in Figure 2 (a). Figure 2 (b) is the shape information of this frame image encoded by MPEG-4. Figure 2 (c) is the incorrect shape information obtained by the receiving end due to an error in transmission.
As already explained in the second part, the existing methods may not be able to solve this situation very well. If a very serious transmission error or a high packet loss rate occurs, the shape information will be severely damaged, affecting the correct decoding of video objects. Using the two algorithms proposed in this paper, the shape information as a watermark is extracted from the received background green component. The premise of this method is the correct transmission of the background. Figure 3 (a) and Figure 3 (b) are the effect of the video background object correctly decoded at the decoding end after embedding by the frequency domain method, and the binary mask image correctly extracted and restored, Figure 3 (c) and Figure 3 (d) is the effect map embedded by the spatial method and the extracted binary mask map.

Use the similarity measure to compare the recovered mask map with the original mask map to see how effective this article is. The similarity measurement formula is formula (3). The experimental results show that the resilience of the recovered masks of the frequency domain method and the space domain method is very close to the original image. The similarity of the background image of the spatial domain method is also slightly better than that of the frequency domain method. The signal-to-noise ratio of the background image after the frequency domain method is 31.14, and the signal-to-noise ratio of the background image after the spatial domain method is 34.88. In comparison, the spatial domain method proposed in this paper is better than the frequency domain method. People often have lower requirements for video pictures than static pictures, and people pay less attention to video background objects in object-based coding, so the visual loss of video background objects can also be tolerated.

5 Conclusion
The algorithm proposed in this paper is a novel shape information error concealment method combined with digital watermarking. If the shape information loss at the receiving end is very serious, especially the shape mask of I-VOP, if it is damaged, the subsequent VOP prediction will be seriously damaged. According to the two watermarking algorithms proposed in this paper, a mask with a high similarity to the original mask can be obtained, and then objects without approximation and without loss can be obtained. However, the algorithm still has some shortcomings: this method is based on the premise that there is no loss in the background area or a certain packet loss rate, and there is a certain quality loss on the image of the background area. Striving to find a more robust embedding method and a more tolerable embedding transparency is the next step of research work.
Magnetic USB Cable refers to the magnet male and female to suction mode to connect the charging effect of the charging cable. Rely on the magnet magnetic attraction, traditional cable connector is separated from the cable body, both through magnetic in automatic adsorption within a certain distance, so called magnetic suction cable magnetic suction cable, magnetic suction cable, magnetic suction charging cable, etc.so that we can realize single hand plug cable, and in the process of actual use, the magnetic suction charging cable is safer than ordinary USB Cable.
Interface widely applicable to mainstream models.Thin small size for wide, differs from the traditional life of the common data interface,a new type of magnetic suction cable charging interface on the size of the thin body, even mobile phones with a set of use, magnetic suction cable also apply to the charging 90% of cell phone sets, don't need to pick a set can be used directly, so it is suitable for use in the increasingly miniaturization of electronic equipment, Can withstand more than 50,000 times of repeated insertion and removal. Fast transmission speed, perfectly compatible with mobile phone data transmission.
It is easy to use,can be single-hand operation,regardless of positive and negative, random insertion, the error rate is zero, even if the 3-year-old children can not be inserted wrong, very suitable for driving, sleeping and other life scenarios. The appearance of magnetic charging cable has impacted the market of Usb C Cable, because magnetic charging cable is much better than ordinary data cable, bringing too much convenience to life. The feeling of user experience has also risen, and more people begin to enjoy the sense of convenience brought by magnetic charging cable to life.

Magnetic Usb Cable,5A Usb Cable,Magnetic Micro Usb Cable,Led Magnetic Charging Cable
Henan Yijiao Trading Co., Ltd , https://www.yijiaousb.com