Semantic segmentation is a task in computer vision. Semantic segmentation allows us to understand images in more detail than image classification and object detection. This understanding of details is very important in many areas, including autopilot, robotics, and image search engines. Andy Chen and Chaitanya Asawa from Stanford University have provided us with detailed information on what conditions are needed for precise semantic segmentation. This article will focus on the use of deep learning model to achieve supervised semantic segmentation.
How does humanity describe a scene? We may say "There is a table under the window" or "There is a lamp on the right side of the sofa." Splitting the scene into separate entities is the key to understanding an image. It allows us to understand the behavior of the target object.
Of course, the target detection method can help us draw a bounding box around a specific entity. However, if you want to understand the scene like humans, you need to monitor and mark the bounding box of each entity and make it accurate to the pixel level. This task has become more and more important because we started to create self-driving cars and smart robots, all of which require a precise understanding of the surrounding environment. Andy Chen and Chaitanya Asawa from Stanford University have provided us with detailed information on what conditions are needed for precise semantic segmentation. The following is the compilation of Logic.
What is semantic segmentation
Semantic segmentation is a task in computer vision. In this process, we classify different parts of visual input into different categories according to their semantics. Through "semantic understanding", each category has certain practical significance. For example, we may want to extract all the pixels of the car in the figure and then paint the colors blue.

Although unsupervised methods such as clustering can be used for segmentation, such results are not semantically classified. These methods are not divided according to training methods, but follow a more general approach.
Semantic segmentation allows us to understand images in more detail than image classification and object detection. This understanding of details is very important in many areas, including autopilot, robotics, and image search engines. This article will focus on the use of deep learning models for supervised semantic segmentation.
Data sets and standards
The data sets that are often used to train semantic segmentation models are:
Pascal VOC 2012: There are 20 categories, including people, transportation, etc. The purpose is to divide the target object category or background.
Cityscapes: collections of landscape data from 50 cities.
Pascal Context: There are more than 400 indoor and outdoor scenes.
Stanford Background Dataset: This data set is all composed of outdoor scenes, but each picture has at least one foreground.

The standard used to evaluate the performance of semantic segmentation algorithms is Intersection Over Union (IoU), where IoU is defined as:
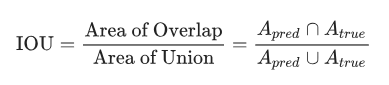
This standard ensures that we can not only capture each target but also accomplish this task very accurately.
Semantic segmentation process (Pipeline)
In the high-level process, the semantic segmentation model is usually applied as follows:
Input → Classifier → Post-Process → Final Result
We will discuss the classifier and post-processing process in detail later.
Structure and segmentation method
Classification using convolutional neural networks
The most recent structure for semantic segmentation is the Convolutional Neural Network (CNN), which first assigns the initial category label to each pixel. The convolutional layer can effectively capture the local features of the image while embedding such layers in layers. CNN tries to extract a wider structure. As more and more convolutional layers capture increasingly complex image features, a convolutional neural network can encode the content in the image into a compact representation.
But to map individual pixels to tags, we need to enhance the standard CNN encoder in a codec-decoder setup. In this setup, the encoder uses convolution and pooling layers to reduce the width and height of the image to a lower dimensional representation. It is then input into the decoder, and the "recovery" space dimension is upsampled, expanding the size of the representation at each decoder step. In some cases, the steps in the middle of the encoder are used to aid the steps of the decoder. Finally, the decoder generates a set of tags representing the original image.

SCNet encoding-decoding setup
In many semantic segmentation structures, the loss function that CNN wants to minimize is the cross-entropy loss. This objective function measures the distance between the predicted probability distribution of each pixel and its actual probability distribution.
However, the cross-entropy loss is not ideal for semantic segmentation because the final loss of one image is only the sum of each pixel loss, while the cross-entropy loss is not parallel. Because cross-entropy loss cannot add more advanced structures between pixels, labels that minimize cross-entropy often become incomplete or distorted, requiring post-processing.
Improve with conditional randomness
The original tags in the CNN are often patched images, where there may be some places where the tags are wrong and do not match the surrounding pixel tags. To solve this incoherent problem, we can apply a technique that makes it smooth. We want to ensure that the image area where the target object is located is coherent, and that any pixel has the same label as its surroundings.
To solve this problem, some architectures use Conditional Random Fields (CRFs), which use the similarity of pixels in the original image to adjust CNN's label.
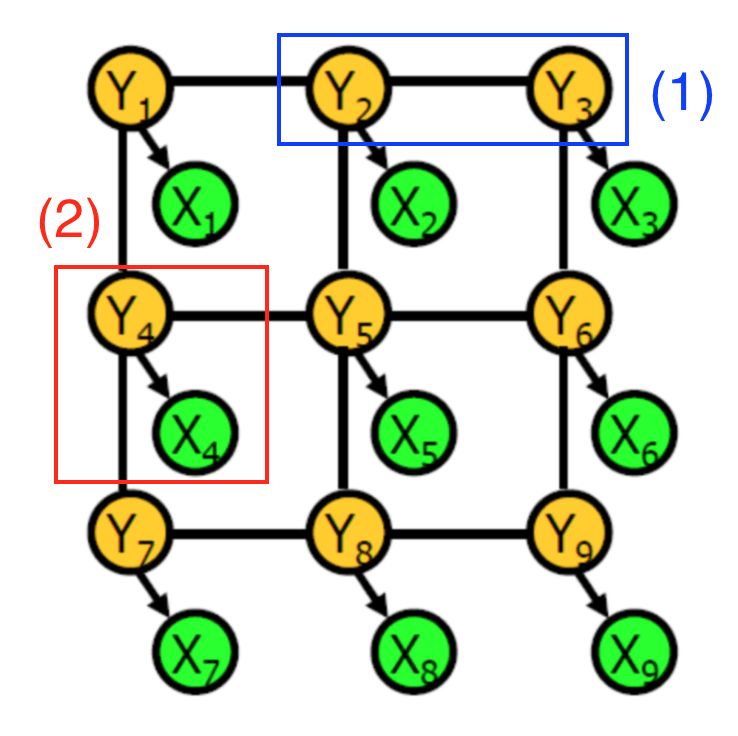
Example of conditional random fields
A conditional random field is a graph composed of random variables. In this context, each node represents:
CNN tags for specific pixels (green)
The actual object tag for a specific pixel (yellow)
There are two types of information encoded in each connection:
Blue: Correlation between actual tags in two pixels
Red: Dependency between CNN's original prediction and the actual label of a given pixel
Each dependency is related to potential. It is a function represented by two related random variables. For example, when the actual labels of adjacent pixels are the same, the first type of dependency is more likely. More directly, the object tag serves as a hidden variable that generates an observable CNN pixel tag based on some probability distribution.
To use CRF to adjust labels, we first learn the parameters of the image model using training data. Then we adjust the parameters again to maximize the probability. The inferred output of the CRF is the final target tag of the original image pixel.
In practice, the CRF graphics are fully connected, which means that even if the pixels opposite to the nodes are far apart, they can still be on one link. This graph has billions of connecting lines and is very computationally expensive when calculating actual inferences. The CRF architecture will be inferred using efficient estimation techniques.
Classifier structure
The CRF adjustment after the CNN classification is only an example of the semantic segmentation process. Many research papers have discussed variants of this process:
U-Net enhances its training data by generating a distorted version of the original training data. This step allows CNN's encoder-decoder to be more stable in dealing with such distortions while learning in fewer training images. When trained in less than 40 medical images, the model's IoU score still reached 92%.
DeepLab combined the CNN encoder-decoder and CRF adjustments to generate its object tag (the author emphasized the upsampling during decoding). Hollow convolution uses each different sized filter, allowing each layer to capture features of different sizes. On the Pascal VOC 2012 test set, the average IoU score for this structure was 70.3%.
Dilation10 is an alternative to void convolution. Its average IoU score on the Pascal VOC 2012 test set was 75.3%.
Other training processes
Now we look at the recent training case. Unlike the various elements that contain optimization, these methods are end-to-end.
Fully Differential Conditional Random
The CRF-RNN model proposed by Zheng et al. introduced a method that combines classification and post-processing into an end-to-end model, optimizing both phases simultaneously. Therefore, for example, the weight parameters of the CRF Gaussian kernel can be automatically learned. They emerged as an inference approximation algorithm as a convolution to achieve this goal, while using a recurrent neural network to simulate the fully iterative nature of the inference algorithm.
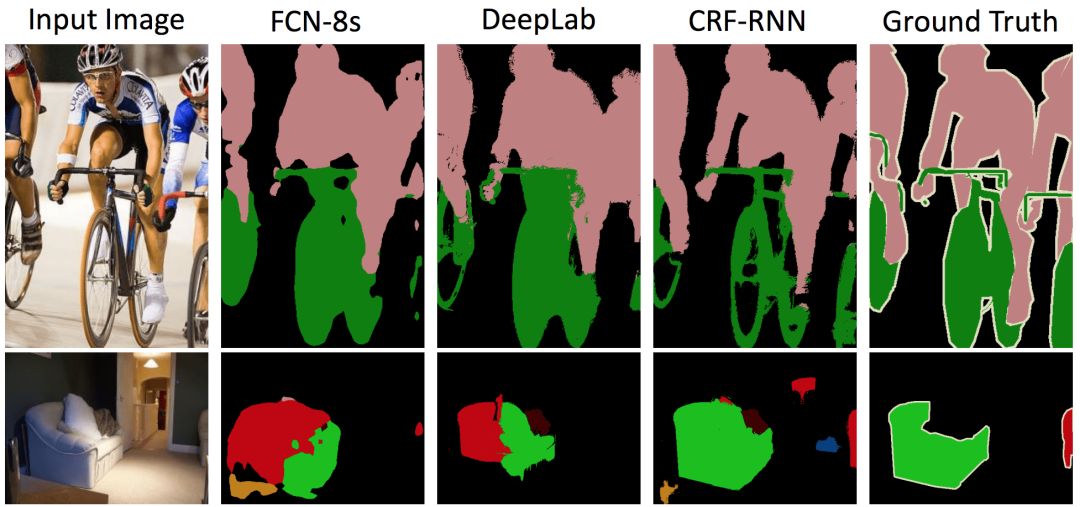
Separated two pictures generated by FCN-8s, DeepLab, and CRF-RNN, respectively
Confrontation training
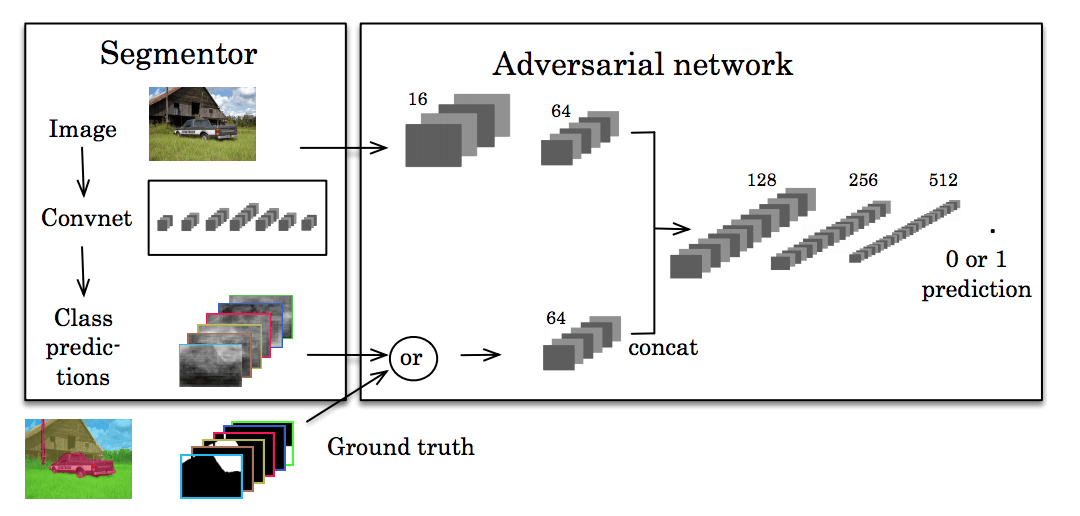
Recently, there have also been studies using countermeasures to help develop a higher degree of consistency. Inspired by the generation of confrontational networks, Luc et al. trained a standard CNN for semantic segmentation and a network of confrontation, trying to learn the difference between standard segmentation and predictive segmentation. The purpose of splitting the network is to generate a semantic segmentation that the network cannot resolve.
The central idea here is that we want our segmentation to look as real as possible. If other networks can easily see through, then our segmentation prediction is not good enough.
Split over time
How can we predict the future of the target object? We can model the segmentation action in a scene. This can be applied to robots or automated vehicles that need to model the movement of objects and plan accordingly.
Luc et al. discussed this issue in 2017, in which they stated that directly predicting future semantic partitions will generate better performance than predicting future frames and then segmenting them.
They used an automatic regression model to predict the next segment using past segmentation, and so on.
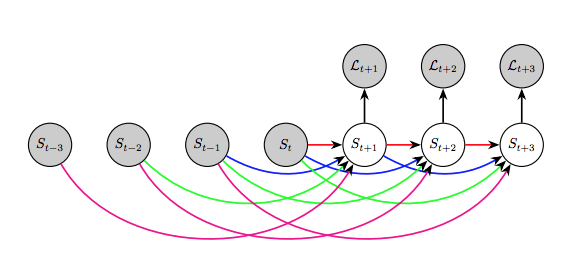
It was found that the long-term performance of this method is not very good, and it works well in the short and medium term.
Conclusion
Many of these methods, such as U-Net, follow an infrastructure: we refer to deep learning (or convolutional networks) and post-processing with traditional probabilistic methods. Although the original output of the convolutional network is not perfect, post-processing can adjust the segmented labels to human-like levels.
Other methods, such as confrontation learning, can be seen as a powerful end-to-end solution for segmentation. Unlike previous CRF steps, end-to-end technology does not require human modeling to adjust the original prediction. Because the current performance of these technologies is better than multi-step solutions, there will be more research on end-to-end algorithms in the future.
switch and socket, Wall switch and socket, push switch and socket
Guangdong Shunde Langzhi Trading CO., Ltd , https://www.langzhielectrical.com